- Published on
书籍-Elasticsearch笔录
Elastic Stack 全景
Elasticsearch 演进史
- 过去
- Elasticsearch 单兵作战
- 现在
- E, L, K, B 四驾马车形成合力—Elastic Stack
- 未来
- 一站式解决方案提供商
Elastic Stack 组成
- Elasticsearch
- 核心的分布式搜索和分析引擎
- Logstash
- 数据处理管道
- 输入
- 过滤
- 输出
- 三段论灵活同步数据
- 数据处理管道
- Kibana
- 界面交互开发工具和管理工具
- 数据可视化分析利器
- Beats
- 多种单一用途数据采集器
- Filebeat
- Metricbeat
- Packetbeat
- 多种单一用途数据采集器
Elastic Stack 的应用场景
- 全文检索场景
- 日志分析场景
- 商业智能场景
Elasticsearch 竞品分析
- Apache Solr
- Splunk
- OpenSearch
- Doris
- ClickHouse
Elasticsearch 核心概念
Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群Document&field:文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段(类似数据库行);Index:索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document;(类似数据库库)Type:类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。表)。
shard和replica的解释
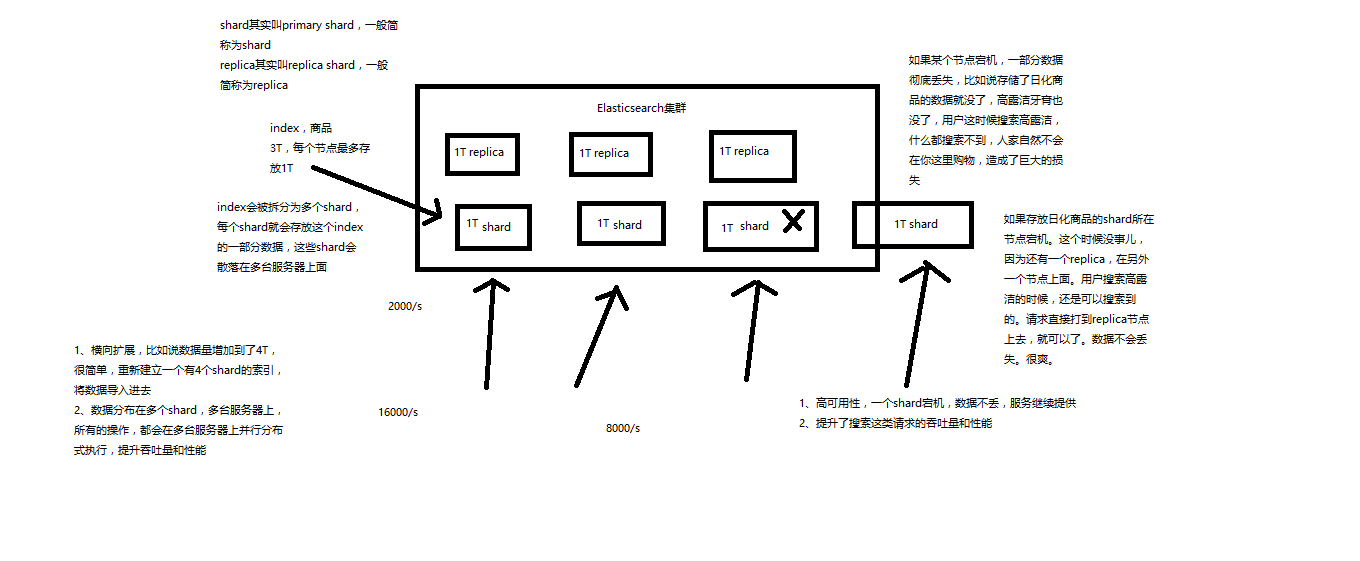
shard&replica机制梳理
index包含多个shard- 每个
shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力 - 增减节点时,
shard会自动在nodes中负载均衡 primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shardreplica shard是primary shard的副本,负责容错,以及承担读请求负载primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shardprimary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
索引
- 数据逻辑容器
- 包含一组相似结构的文档
- 具有唯一名称
- 搜索、更新、删除操作
快速查看集群中有哪些索引
GET /_cat/indices?v
# 创建索引
PUT /test_index?pretty
# 删除索引
DELETE /test_index?pretty
分片
- 解决单节点瓶颈问题
副本
- 提高查询吞吐量或实现高可用
快速检查集群的健康状况
GET /_cat/health?v
如何快速了解集群的健康状况?green、yellow、red?
green:每个索引的primary shard和replica shard都是active状态的;yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态;red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了。
为什么现在会处于一个yellow状态?
我们现在就一台服务器,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配5个primary shard和5个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana自己建立的index是1个primary shard和1个replica shard。当前就一个node。
文档
- 将数据以文档为单位存储在索引中
- JSON 格式
- 键值对组成
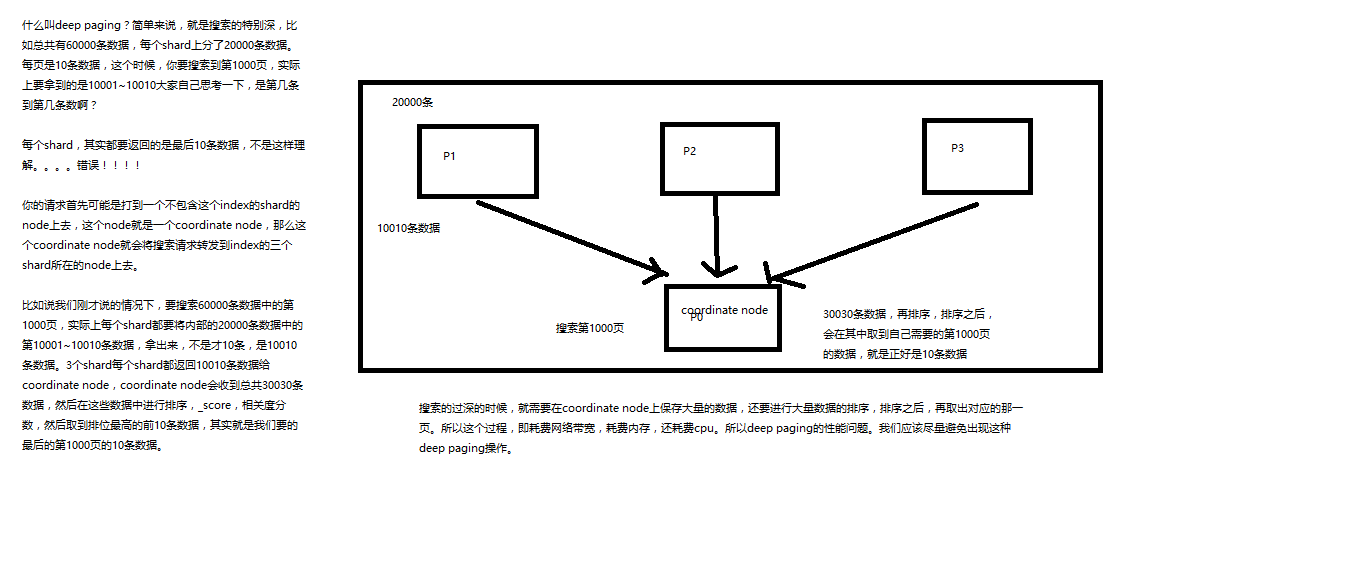
分页查询
- 使用es进行分页搜索的语法
GET /_search?size=10
GET /_search?size=10&from=0
GET /_search?size=10&from=20
分页的上机实验
GET /test_index/test_type/_search
我们假设将这9条数据分成3页,每一页是3条数据,来实验一下这个分页搜索的效果
GET /test_index/test_type/_search?from=0&size=3
映射
- 表结构
- 包含字段和字段类型
分词
- 构建倒排索引的基石
- 不同的分词方法需要不同的分词器
常用查询汇总
# 根据id 进行查询
GET /test_index/_doc/wpmzB5EBfH0qNHSxjFjK
# 根据条件来查询
GET /test_index/_doc/_search?q=name:yagao&sort=price:desc
# ====== query DSL ======
# 查询所有的商品
GET /career_plan_sku_index_50/_search
{
"query": {"match_all": {}}
}
# 指定要查询出来商品的名称和价格就可以
GET /career_plan_sku_index_50/_search
{
"query": {"match_all": {}},
"_source": ["skuName", "basePrice"]
}
# 分页查询商品
GET /career_plan_sku_index_50/_search
{
"query": {"match_all": {}},
"from": 0,
"size": 10
}
# 查询名称包含内衣的商品,同时按照价格降序排序
GET /career_plan_sku_index_50/_search
{
"query": {"match": {
"category": "内衣"
}},
"sort": [
{
"basePrice": {
"order": "desc"
}
}
]
}
GET /career_plan_sku_index_50/_search
{
"query": {"match_all": {}}
}
# highlight search(高亮搜索结果)
GET /career_plan_sku_index_50/_search
{
"query" : {
"match" : {
"skuName" : "La Perla"
}
},
"highlight": {
"fields" : {
"skuName" : {}
}
}
}
# phrase search(短语搜索)
GET /career_plan_sku_index_50/_search
{
"query" : {
"match_phrase" : {
"skuName" : "NERO PERLA"
}
}
}
# ull-text search(全文检索)
GET /career_plan_sku_index_50/_search
{
"query": {
"match": {
"skuName": "La Perla"
}
}
}
# query filter 搜索商品名称包含韩都衣舍,而且售价大于200元的商品
GET /career_plan_sku_index_50/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"skuName" : "韩都衣舍"
}
},
"filter" : {
"range" : {
"basePrice" : { "gt" : 200 }
}
}
}
}
}
# 第五个数据分析需求:按照指定的价格范围区间进行分组,然后在每组内再按照tag进行分组,最后再计算每组的平均价格
GET /career_plan_sku_index_50/_search
{
"size": 0,
"aggs": {
"group_by_basePrice": {
"range": {
"field": "basePrice",
"ranges": [
{
"from": 0,
"to": 100
},
{
"from": 100,
"to": 500
},
{
"from": 500,
"to": 1000
}
]
},
"aggs": {
"group_by_category": {
"terms": {
"field": "category"
},
"aggs": {
"average_basePrice": {
"avg": {
"field": "basePrice"
}
}
}
}
}
}
}
}
# 第四个数据分析需求:计算每个category下的商品的平均价格,并且按照平均价格降序排序
GET /career_plan_sku_index_50/_search
{
"size": 0,
"aggs": {
"group_by_category": {
"terms": {"field": "category"}
, "aggs": {
"avg_basePrice": {
"avg": {"field": "basePrice"}
}
}
}
}
}
# 第三个聚合分析的需求:先分组,再算每组的平均值,计算每个category下的商品的平均价格
GET /career_plan_sku_index_50/_search
{
"size": 0,
"aggs": {
"group_by_category": {
"terms": {"field": "category"}
, "aggs": {
"avg_basePrice": {
"avg": {"field": "basePrice"}
}
}
}
}
}
# 第二个聚合分析的需求:对名称中包含La Perla的商品,计算每个category下的商品数量
GET /career_plan_sku_index_50/_search
{
"size": 0,
"query": {
"match": {
"skuName": "La Perla"
}
},
"aggs": {
"all_category": {
"terms": {
"field": "category"
}
}
}
}
# 计算每个category下的商品数量
GET /career_plan_sku_index_50/_search
{
"size": 0,
"aggs": {
"all_category": {
"terms": { "field": "category" }
}
}
}
# 批量查询 mget
GET /career_plan_sku_index_50/_search
GET /_mget
{
"docs" : [
{
"_index" : "career_plan_sku_index_50",
"_id" : "wpmzB5EBfH0qNHSxjFjK"
},
{
"_index" : "career_plan_sku_index_50",
"_id" : "xpmzB5EBfH0qNHSxjFjK"
}
]
}
GET /career_plan_sku_index_50/_mget
{
"ids": ["wpmzB5EBfH0qNHSxjFjK", "xpmzB5EBfH0qNHSxjFjK"]
}
query string search | 搜索全部商品:GET /test_index/_search
took:耗费了几毫秒;timed_out:是否超时,这里是没有;_shards:数据拆成了5个分片,所以对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard也可以);hits.total:查询结果的数量,3个document;hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高;hits.hits:包含了匹配搜索的document的详细数据。
query DSL
DSL:Domain Specified Language:特定领域的语言;http request body:请求体,可以用json的格式来构建查询语法,比较方便,可以构建各种复杂的语法,比query string search肯定强大多了查询所有的商品。
query filter
full-text search
phrase search
- 跟全文检索相对应,相反,全文检索会将输入的搜索串拆解开来,去倒排索引里面去一一匹配,只要能匹配上任意一个拆解后的单词,就可以作为结果返回phrase search,要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回。
highlight search
document是如何路由到shard 上的
- 路由算法:
shard = hash(routing) % number_of_primary_shards
举个例子,一个index有3个primary shard,P0,P1,P2,每次增删改查一个document的时候,都会带过来一个routing number,默认就是这个document的_id(可能是手动指定,也可能是自动生成) routing = _id,假设_id=1,会将这个routing值,传入一个hash函数中,产出一个routing值的hash值,hash(routing) = 21,然后将hash函数产出的值对这个index的primary shard的数量求余数, 21 % 3 = 0 就决定了,这个document就放在P0上。
决定一个document在哪个shard上,最重要的一个值就是routing值,默认是_id,也可以手动指定,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的无论hash值是几, 无论是什么数字,对number_of_primary_shards求余数,结果一定是在0~number_of_primary_shards-1之间这个范围内的。0,1,2。
_id or custom routing value
默认的routing就是_id,也可以在发送请求的时候,手动指定一个routing value,比如说put /index/type/id?routing=user_id 手动指定routing value是很有用的,可以保证说,某一类document一定被路由到一个shard上去,那么在后续进行应用级别的负载均衡,以及提升批量读取的性能的时候,是很有帮助的。
Elasticsearch 索引
索引定义
- 类似于 MySQL 中的表
- 命名规范
- 包含:
- settings
- mappings
- alias
索引操作
- 增
- 删
- 改
- 查
索引别名
- 别名定义
- 为索引或模板指定别名
- 别名实现
- 多索引检索实现
- 常见问题
索引模板
- 索引模板定义
- 索引模板基础操作
- 增
- 删
- 改
- 查
- 动态模板实战
Elasticsearch 映射
映射的定义
- 数据类型
- 基本类型
- binary
- boolean
- keywords
- number
- date
- alias
- text
- 复杂类型
- Array
- Object
- Nested
- Join
- Flattened
- 坐标类型
- 专用类型
- IP 类型
- completion 类型
- 多字段类型
- multi_fields
- 基本类型
- 映射类型
- 动态映射
- 静态映射
多表关联设计
- Nested 嵌套类型
- Join 父子文档类型
- 宽表冗余存储
- 业务端关联
内部数据结构
- 倒排索引
- 正排索引
- fielddata
- _source 字段
- store 字段
null_value
- 含义
- 注意事项
- 核心字段
各种类型的文件比较
| 比较 | Nested 嵌套类型 | Join 父子文档类型 | 宽表冗余存储 | 业务端关联 |
|---|---|---|---|---|
| 适用场景 | 一对少量、子文档偶尔更新、查询频繁 | 子文档频繁更新 | 一对多或者多对多 | 数据量少 |
| 优点 | 读取性能高(因为文档存储在一起) | 父子文档可独立更新,互不影响 | 以空间换时间,字段冗余构造好 | 数据量少时,用户体验好 |
| 缺点 | 查询相对较慢 | Join 关系的维护也耗费内存,读取性能比 Nested 还差 | 字段冗余造成存储空间的浪费 | 数据量多,两次查询耗时较长,影响用户体验 |
官方文档中的搜索速度常见的优化点
官⽅⽂档 https://www.elastic.co/guide/en/elasticsearch/reference/7.9/tune-for-search-speed.htm
⽂档中给出了下⾯⼏个点
- ⾸先elasticsearch的性能是特别棒的,在合理的机器配置下,是不怎么需要做优化的。当我们的业务遇 到查询瓶颈时再根据业务场景的特点从官⽅⽂档说的⼏个点中看⼀下哪个是能做的再去优化。
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | Give memory to the filesystem cache | elasticsearch的查询cache是保存在操作系统的物理内存中的, 需要给操作系统的物理内存保留⾜够的空间。⼀般都是把机器内 存的⼀般给elasticsearch的jvm堆,另⼀半给预留给操作系统的 物理内容。现在我们后⾯会对这⼀点⽤⼀个例⼦来演示。 |
| 2 | Use faster hardware | 搜索性能对硬件的要求主要体现在2个⽅⾯:磁盘IO性能和CPU性 能对于普通的搜索,磁盘IO的性能是最影响搜索性能的 对与计算⽐较多的搜索,CPU的性能会是⼀个瓶颈,这⼀点我们在可以选择的配置范围内,优先选⽤更⾼性能的硬件就⾏。 |
| 3 | Document modeling | 这个点是和具体业务的数据模型相关的,不要⽤嵌套类型的字 段,避免查询时的join操作。就类似在设计mysql的表时就是打破 那⼏个范式⼀样 |
| 4 | Search as few fields as possible | 这个适⽤的范围⽐较窄,⽂档中介绍了copy_to属性 |
| 5 | Pre-index data | 适⽤于数字类型的字段+经常做范围搜索的场景 把数字类型的字段转成keyword类型的字段 把range查询转换为terms查询 |
| 6 | Consider mapping identifiers as keyword | ⽐如我们把原本是long类型的skuId,设置为keyword类型的 |
| 7 | Avoid scripts | 我们⼏乎没有使⽤scripts的情况 |
| 8 | Search rounded dates | 对于时间类型的查询,我们把时间四舍五⼊到分钟级别⼩时级别 提升缓存命中率。 |
| 9 | Force-merge read-only indices | 对于内容不会再变化的索引,执⾏ force merge操作把多个 segment合并成⼀个segment,查询的时候只从⼀个segament 查,不⽤再查询多个segment然后合并结果。 最典型的场景就是⽐如每天都⽣成⼀个新的索引这种情况 |
| 10 | Warm up global ordinals | 在refresh的时候就预先构建 global ordinals 这种数据结构 global ordinals是⽤来在keyword类型字段上做terms聚合操作的 但是这个东⻄也会直接增⼤内存占⽤,特定情况下可以试试 |
| 11 | Warm up the filesystem cache | ⼀般是ealsticsearch重启的时候⽂件系统的缓存是空空的,通过 配置index.store.preload来配置索引的那些字段要⾃动加再到内 存中。 要是内存⼩的话需要慎⽤这个。 |
| 12 | Use index sorting to speed up conjunctions | 适⽤与类似枚举类型字段的场景,在整个索引中⽂档的某个字段 取值范围是固定的,很多都是重复的。 |
| 13 | Use preference to optimize cache utilization | lasticsearch每个节点都有独⾃的各种类型的缓存,使⽤⼀个 preference字段标记⽤户或者会话,把请求路由到固定节点 https://www.elastic.co/guide/en/elasticsearch/reference/7. 9/search-shard-routing.html |
| 14 | Replicas might help with throughput, but not always | 查询速度和可⽤性的关系 |