- Published on
JUC容器类-06
6.1 线程安全的同步容器类
Java同步容器类通过Synchronized(内置锁)来实现同步的容器,比如Vector、HashTable以及SynchronizedList等容器。线程安全的同步容器类主要有Vector、Stack、HashTable等。另外,Java还提供了一组包装方法,将一个普通的基础容器包装成一个线程安全的同步容器。例如通过Collections.synchronized包装方法能将一个普通的SortedSet容器包装成一个线程安全的SortedSet同步容器。
1.通过synchronizedSortedSet静态方法包装出一个同步容器
下面的例子调用java.util.Collections.synchronizedSortedSet()静态方法包装出一个线程安全的同步容器:
public class CollectionsDemo {
public static void main(String[] args) throws InterruptedException {
// 创建一下有序集合
SortedSet<String> elementSet = new TreeSet<String>();
// 增加元素
elementSet.add("element 1");
elementSet.add("element 2");
// 将 elementSet 包装成一个同步容器
SortedSet<String> sorset = Collections.synchronizedSortedSet(elementSet);
//输出容器中的元素
System.out.println("SortedSet is :" + sorset);
CountDownLatch latch = new CountDownLatch(5);
for (int i = 0; i < 5; i++) {
int finalI = i;
ThreadUtil.getCpuIntenseTargetThreadPool()
.submit(() -> {
// 向同步容器中增加一个元素
sorset.add("element " + (3 + finalI));
Print.tco("add element" + (3 + finalI));
latch.countDown();
});
}
latch.await();
//输出容器中的元素
System.out.println("SortedSet is :" + sorset);
}
}
同步容器面临的问题
可以通过查看Vector、HashTable、java.util.Collections同步包装内部类的源码,发现这些同步容器实现线程安全的方式是:在需要同步访问的方法上添加关键字synchronized。
6.2 JUC高并发容器
什么是高并发容器
JUC高并发容器是基于非阻塞算法(或者无锁编程算法)实现的容器类,无锁编程算法主要通过CAS(Compare And Swap)+Volatile组合实现,通过CAS保障操作的原子性,通过volatile保障变量内存的可见性。无锁编程算法的主要优点如下:
(1)开销较小:不需要在内核态和用户态之间切换进程。
(2)读写不互斥:只有写操作需要使用基于CAS机制的乐观锁,读读操作之间可以不用互斥。
JUC包中提供了List、Set、Queue、Map各种类型的高并发容器,如ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkipListSet、CopyOnWriteArrayList和CopyOnWriteArraySet。在性能上,ConcurrentHashMap通常优于同步的HashMap,ConcurrentSkipListMap通常优于同步的TreeMap。当读取和遍历操作远远大于列表的更新操作时,CopyOnWriteArrayList优于同步的ArrayList。
6.2.1 List
JUC包中的高并发List主要有CopyOnWriteArrayList,对应的基础容器为ArrayList。
CopyOnWriteArrayList相当于线程安全的ArrayList,它实现了List接口。在读多写少的场景中,其性能远远高于ArrayList的同步包装容器。
6.2.2 Set
JUC包中的Set主要有CopyOnWriteArraySet和ConcurrentSkipListSet。
·CopyOnWriteArraySet继承自AbstractSet类,对应的基础容器为HashSet。其内部组合了一个CopyOnWriteArrayList对象�,它的核心操作是基于CopyOnWriteArrayList实现的。
·ConcurrentSkipListSet是线程安全的有序集合,对应的基础容器为TreeSet。它继承自AbstractSet,并实现了NavigableSet接口。ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的。
6.2.3 Map
JUC包中Map主要有ConcurrentHashMap和ConcurrentSkipListMap。
·ConcurrentHashMap对应的基础容器为HashMap。JDK 6中的ConcurrentHashMap采用一种更加细粒度的“分段锁”加锁机制,JDK 8中采用CAS无锁算法。
·ConcurrentSkipListMap对应的基础容器为TreeMap。其内部的Skip List(跳表)结构是一种可以代替平衡树的数据结构,默认是按照Key值升序的。
6.2.4 Queue
JUC包中的Queue的实现类包括三类:单向队列、双向队列和阻塞队列。
·ConcurrentLinkedQueue是基于列表实现的单向队列,按照FIFO(先进先出)原则对元素进行排序。新元素从队列尾部插入,而获取队列元素则需要从队列头部获取。
·ConcurrentLinkedDeque是基于链表的双向队列,但是该队列不允许null元素。作为双向队列,ConcurrentLinkedDeque可以当作“栈”来使用,并且高效地支持并发环境。
除了提供普通的单向队列、双向队列外,JUC拓展了队列,增加了可阻塞的插入和获取等操作,提供了一组阻塞队列,具体如下:
·ArrayBlockingQueue:基于数组实现的可阻塞的FIFO队列。
·LinkedBlockingQueue:基于链表实现的可阻塞的FIFO队列。
·PriorityBlockingQueue:按优先级排序的队列。
·DelayQueue:按照元素的Delay时间进行排序的队列。
·SynchronousQueue:无�缓冲等待队列。
6.3 JUC 容器类的使用
6.3.1 CopyOnWriteArrayList的使用
Collections可以将基础容器包装为线程安全的同步容器,但是这些同步容器包装类在进行元素迭代时并不能进行元素添加操作。下面是一个简单的例子:
public class CopyOnWriteArrayListTest {
//并发操作的任务目标
public static class CocurrentTarget implements Runnable {
//并发操作的目标队列
List<String> targetList = null;
public CocurrentTarget(List<String> targetList) {
this.targetList = targetList;
}
@Override
public void run() {
Iterator<String> iterator = targetList.iterator();
//迭代操作
while (iterator.hasNext()) {
// 在迭代操作时,进行列表的修改
String threadName = currentThread().getName();
Print.tco("开始往同步队列加入线程名称:" + threadName);
targetList.add(threadName);
}
}
}
//测试同步队列:在迭代操作时,进行列表的修改
@Test
public void testSynchronizedList() {
List<String> notSafeList = Arrays.asList("a", "b", "c");
List<String> synList = Collections.synchronizedList(notSafeList);
CocurrentTarget synchronizedListListDemo = new CocurrentTarget(synList);
//10个线程并发
for (int i = 0; i < 10; i++) {
new Thread(synchronizedListListDemo, "线程" + i).start();
}
//主线程等待
sleepSeconds(1000);
}
}
可使用CopyOnWriteArrayList替代Collections.synchronizedList同步包装实例,具体的代码如下:
//测试CopyOnWriteArrayList
@Test
public void testcopyOnWriteArrayList() {
List<String> notSafeList = Arrays.asList("a", "b", "c");
//创建一个 CopyOnWriteArrayList 队列
List<String> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
copyOnWriteArrayList.addAll(notSafeList);
//并发操作目标
CocurrentTarget copyOnWriteArrayListDemo = new CocurrentTarget(copyOnWriteArrayList);
for (int i = 0; i < 10; i++) {
new Thread(copyOnWriteArrayListDemo, "线程" + i).start();
}
//主线程等待
sleepSeconds(1000);
}
CopyOnWriteArrayList的原理:
**CopyOnWrite(��写时复制)**就是在修改器对一块内存进行修改时,不直接在原有内存块上进行写操作,而是将内存复制一份,在新的内存中进行写操作,写完之后,再将原来的指针(或者引用)指向新的内存,原来的内存被回收。CopyOnWriteArrayList是写时复制思想的一种典型实现,其含有一个指向操作内存的内部指针array,而可变操作(add、set等)是在array数组的副本上进行的。当元素需要被修改或者增加时,并不直接在array指向的原有数组上操作,而是首先对array进行一次复制,将修改的内容写入复制的副本中。写完之后,再将内部指针array指向新的副本,这样就可以确保修改操作不会影响访问器的读取操作。CopyOnWriteArrayList的原理如图
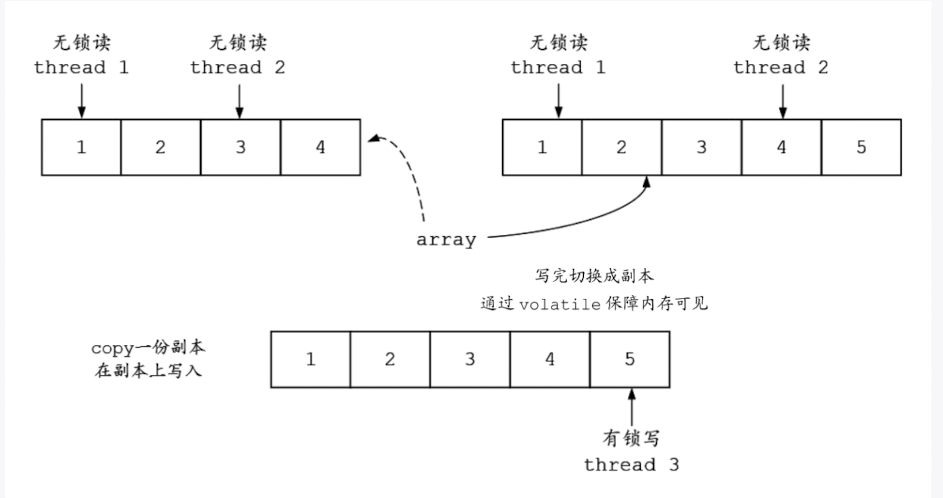
每次添加元素的时候都会重新复制一份新的数组,那就带来了一个问题,就是增加了内存的开销,如果容器的写操作比较频繁,那么其开销就比较大。所以,在实际应用的时候,CopyOnWriteArrayList并不适合进行添加操作。但是在并发场景下,迭代操作比较频繁,CopyOnWriteArrayList就是一个不错的选择。
CopyOnWriteArrayList的优点:
CopyOnWriteArrayList有一个显著的优点,那就是读取、遍历操作不需要同步,速度会非常快。所以,CopyOnWriteArrayList适用于读操作多、写操作相对较少的场景(读多写少),比如可以在进行“黑名单”拦截时使用CopyOnWriteArrayList。
CopyOnWriteArrayList和ReentrantReadWriteLock的比较:
CopyOnWriteArrayList和ReentrantReadWriteLock读写锁的思想非常类似,即读读共享、写写互斥、读写互斥、写读互斥。但是前者相比后者的更进�一步:为了将读取的性能发挥到极致,CopyOnWriteArrayList读取是完全不用加锁的,而且写入也不会阻塞读取操作,只有写入和写入之间需要进行同步等待,读操作的性能得到大幅度提升。
6.3.2 BlockingQueue
在多线程环境中,通过BlockingQueue(阻塞队列)可以很容易地实现多线程之间的数据共享和通信,比如在经典的“生产者”和“消费者”模型中,通过BlockingQueue可以完成一个高性能的实现版本。
BlockingQueue的特点:
阻塞队列与普通队列(ArrayDeque等)之间的最大不同点在于阻塞队列提供了阻塞式的添加和删除方法。
(1)阻塞添加
阻塞添加是指当阻塞队列元素已满时,队列会阻塞添加元素的线程,直到队列元素不满时,才重新唤醒线程执行元素添加操作。
(2)阻塞删除
阻塞删除是指在队列元素为空时,删除队列元素的线程将被阻塞,直到队列不为空时,才重新唤醒删除线程,再执行删除操作。


6.3.3 BlockingQueue 的实现类
BlockingQueue的实现类有ArrayBlockingQueue、DelayQueue、LinkedBlockingDeque、PriorityBlockingQueue、SynchronousQueue等。
1.ArrayBlockingQueue
ArrayBlockingQueue是一个常用的阻塞队列,是基于数组实现的,其内部��使用一个定长数组来存储元素。除了一个定长数组外,ArrayBlockingQueue内部还保存着两个整型变量,分别标识着队列的头部和尾部在数组中的位置。
ArrayBlockingQueue的添加和删除操作共用同一个锁对象,由此意味着添加和删除无法并行运行,这点不同于LinkedBlockingQueue。ArrayBlockingQueue完全可以将添加和删除的锁分离,从而添加和删除操作完全并行。Doug Lea之所以没这样去做,是因为ArrayBlockingQueue的数据写入和获取操作已经足够轻巧。
为什么ArrayBlockingQueue比LinkedBlockingQueue更加常用?前者在添加或删除元素时不会产生或销毁任何额外的Node(节点)实例,而后者会生成一个额外的Node实例。在长时间、高并发处理大批量数据的场景中,LinkedBlockingQueue产生的额外Node实例会加大系统的GC压力。
2.LinkedBlockingQueue
LinkedBlockingQueue是基于链表的阻塞队列,其内部也维持着一个数据缓冲队列(该队列由一个链表构成)。LinkedBlockingQueue对于添加和删除元素分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下,生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
需要注意的是,在新建一个LinkedBlockingQueue对象时,若没有指定其容量大小,则LinkedBlockingQueue会默认一个类似无限大小的容量(Integer.MAX_VALUE),这样的话,生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就已经被消耗殆尽了。
3.DelayQueue
DelayQueue中的元素只有当其指定的延迟时间到了,才能够从队列中获取该元素。DelayQueue是一个没有大小限制的队列,因此往队列中添加数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
DelayQueue的使��用场景较少,但是相当巧妙,常见的例子是使用DelayQueue来管理一个超时未响应的连接队列。
4.PriorityBlockingQueue
基于优先级的阻塞队列和DelayQueue类似,PriorityBlockingQueue并不会阻塞数据生产者,而只会在没有可消费的数据时,阻塞数据的消费者。在使用的时候要特别注意,生产者生产数据的速度绝对不能快于消费者消费数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间。
5.SynchronousQueue
一种无缓冲的等待队列,类似于无中介的直接交易,有点像原始社会中的生产者和消费者,生产者拿着产品去集市销售给产品的最终消费者,而消费者必须亲自去集市找到所要商品的直接生产者,如果一方没有找到合适的目标,那么大家都在集市等待。相对于有缓冲的阻塞队列(如LinkedBlockingQueue)来说,SynchronousQueue少了中间缓冲区(如仓库)的环节。如果有仓库,生产者直接把产品批发给仓库,不需要关心仓库最终会将这些产品发给哪些消费者,由于仓库可以中转部分商品,总体来说有仓库进行生产和消费的吞吐量高一些。反过来说,又因为仓库的引入,使得产品从生产者到消费者中间增加了额外的交易环节,单个产品的及时响应性能可能会降低,所以对单个消息的响应要求高的场景可以使用SynchronousQueue。
声明一个SynchronousQueue有两种不同的方式:公平模式和非公平模式。公平模式的SynchronousQueue会采用公平锁,并配合一个FIFO队列来阻塞多余的生产者和消费者,从而体现出整体的公平特征。非公平模式(默认情况)的SynchronousQueue采用非公平锁,同时配合一个LIFO堆栈(TransferStack内部实例)来管理多余的生产者和消费者。对于后一种模式,如果生产者和消费者的处理速度有差距,就很容易出现��线程饥渴的情况,即可能出现某些生产者或者消费者的数据永远都得不到处理。
6.3.4 ArrayBlockingQueue 的基本使用
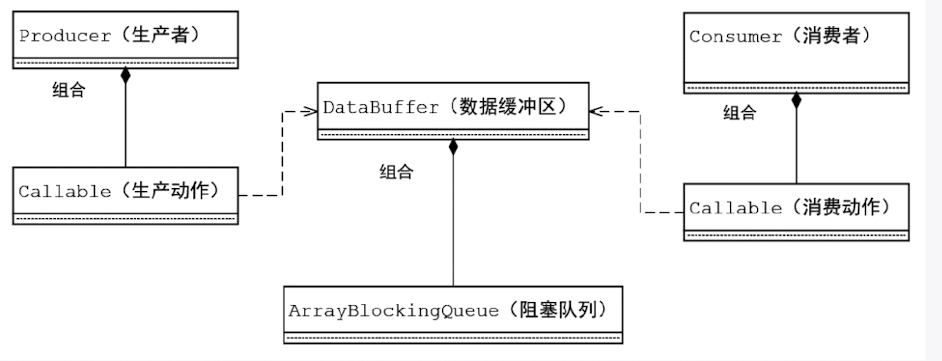
下面通过ArrayBlockingQueue队列实现一个生产者-消费者的案例,通过该案例简单了解其使用方式和方法。具体的代码在前面的生产者和消费者实现基础上进行迭代——Consumer(消费者)和Producer(生产者)通过ArrayBlockingQueue队列获取和添加元素。其中,消费者调用take()方法获取元素,当队列没有元素时就阻塞;生产者调用put()方法添加元素,当队列满时就阻塞。通过这种方式便可以实现生产者-消费者模式,比直接使用等待唤醒机制或者Condition条件队列更加简单。
基于ArrayBlockingQueue的生产者和消费者实现版本具体的UML类图如图:
public class ArrayBlockingQueuePetStore {
public static final int MAX_AMOUNT = 10; //数据区长度
//共享数据区,类定义
static class DateBuffer<T> {
//保存数据
private ArrayBlockingQueue<T> dataList = new ArrayBlockingQueue<>(MAX_AMOUNT);
// 向数据区增加一个元素
public void add(T element) throws Exception {
dataList.put(element);
}
/**
* 从数据区取出一个商品
*/
public T fetch() throws Exception {
return dataList.take();
}
}
public static void main(String[] args) {
Print.cfo("当前进程的ID是" + JvmUtil.getProcessID());
System.setErr(System.out);
//共享数据区,实例对象
DateBuffer<IGoods> dateBuffer = new DateBuffer<>();
//生产者执行的动作
Callable<IGoods> produceAction = () ->
{
//首先生成一个随机的商品
IGoods goods = Goods.produceOne();
//将商品加上共享数据区
dateBuffer.add(goods);
return goods;
};
//消费者执行的动作
Callable<IGoods> consumerAction = () ->
{
// 从PetStore获取商品
IGoods goods = null;
goods = dateBuffer.fetch();
return goods;
};
// 同时并发执行的线程数
final int THREAD_TOTAL = 20;
//线程池,用于多线程模拟测试
ExecutorService threadPool = Executors.newFixedThreadPool(THREAD_TOTAL);
//假定共11条线程,其中有10个消费者,但是只有1个生产者;
final int CONSUMER_TOTAL = 11;
final int PRODUCE_TOTAL = 1;
for (int i = 0; i < PRODUCE_TOTAL; i++) {
//生产者线程每生产一个商品,间隔50ms
threadPool.submit(new Producer(produceAction, 50));
}
for (int i = 0; i < CONSUMER_TOTAL; i++) {
//消费者线程每消费一个商品,间隔100ms
threadPool.submit(new Consumer(consumerAction, 100));
}
}
}
ArrayBlockingQueue中的元素访问存在公平访问与非公平访问两种方式,所以ArrayBlockingQueue可以分别作为公平队列和非公平队列使用:
(1)对于公平队列,被阻塞的线程可以按照阻塞的先后顺序访问队列,即先阻塞的线程先访问队列。
(2)对于非公平队列,当队列可用时,阻塞的线程将进入争夺访问资源的竞争中,也就是说谁先抢到谁就执行,没有固定的先后顺序。
6.3.5 ConcurrentHashMap 的基本使用
ConcurrentHashMap是一个常用的高并发容器类,也是一种线程安全的哈希表。Java 7以及之前版本中的ConcurrentHashMap使用Segment(分段锁)技术将数据分成一段一段存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。Java 8对其内部的存储结构进行了优化,使�之在性能上有进一步的提升。
ConcurrentHashMap和同步容器HashTable的主要区别在锁的类型和粒度上:HashTable实现同步是利用synchronized关键字进行锁定的,其实是针对整张哈希表进行锁定的,即每次锁住整张表让线程独占,虽然解决了线程安全问题,但是造成了巨大的资源浪费。
HashMap和HashTable的问题
基础容器HashMap是线程不安全的,在多线程环境下,使用HashMap进行put操作时,可能会引起死循环,导致CPU利用率飙升,甚至接近100%,所以在高并发情况下是不能使用HashMap的。于是JDK提供了一个线程安全的Map——HashTable,HashTable虽然线程安全,但效率低下。HashTable和HashMap的实现原理几乎一样,区别有两点:
(1)HashTable不允许key和value为null。
(2)HashTable使用synchronized来保证线程安全,包含get()/put()在内的所有相关需要进行同步执行的方法都加上了synchronized关键字,对这个Hash表进行锁定。
HashTable线程安全策略的代价非常大,这相当于给整个哈希表加了一把大锁。当一个线程访问HashTable的同步方法时,其他访问HashTable同步方法的线程就会进入阻塞或轮询状态。若有一个线程在调用put()方法添加元素,则其他线程不但不能调用put()方法添加元素,而且不能调用get()方法来获取元素,相当于将所有的操作串行化。所以,HashTable的效率非常低下。
6.3.6 JDK 1.7的ConcurrentHashMap 和 JDK 1.8版本ConcurrentHashMap 区别
JDK 1.8对ConcurrentHashMap的内部结构进行了改进,改采用数组+链表或红黑树来实现,但是从Segment(分段锁)技术角度来说�,其原理是类似的。
JDK 1.7的ConcurrentHashMap为了进行并发热点的分离,默认情况下将一个table分裂成16个小的table(Segment表示),从而在Segment维度进行比较细粒度的并发控制。实际上,如果并发线程多,这种粒度还是不够细。所以,JDK 1.8的ConcurrentHashMap将并发控制的粒度进一步细化,也就是进一步进行并发热点的分离,将并发粒度细化到每一个桶。既然如此,比较粗粒度的Segment已经没有存在的必要,每一个桶已经变化成实质意义的Segment,所以该结构直接被丢弃。
JDK 1.7的ConcurrentHashMap每一个桶都为链表结构,为了提升节点的访问性能,JDK 1.8引入了红黑树的结构,当桶的节点数超过一定的阈值(默认为64)时,JDK 1.8将链表结构自动转换成红黑树的结构,可以理解为将链式桶转换成树状桶。
ConcurrentHashMap的内部结构的层次关系为ConcurrentHashMap→链式桶/树状桶。这样设计的好处在于,每次访问的时候只需对一个桶进行锁定,而不需要将整个Map集合都进行粗粒度的锁定。
说明:
JDK 1.8的ConcurrentHashMap引入红黑树的原因是:链表查询的时间复杂度为O(n),红黑树查询的时间复杂度为O(log(n)),所以在节点比较多的情况下,使用红黑树可以大大提升性能。