- Published on
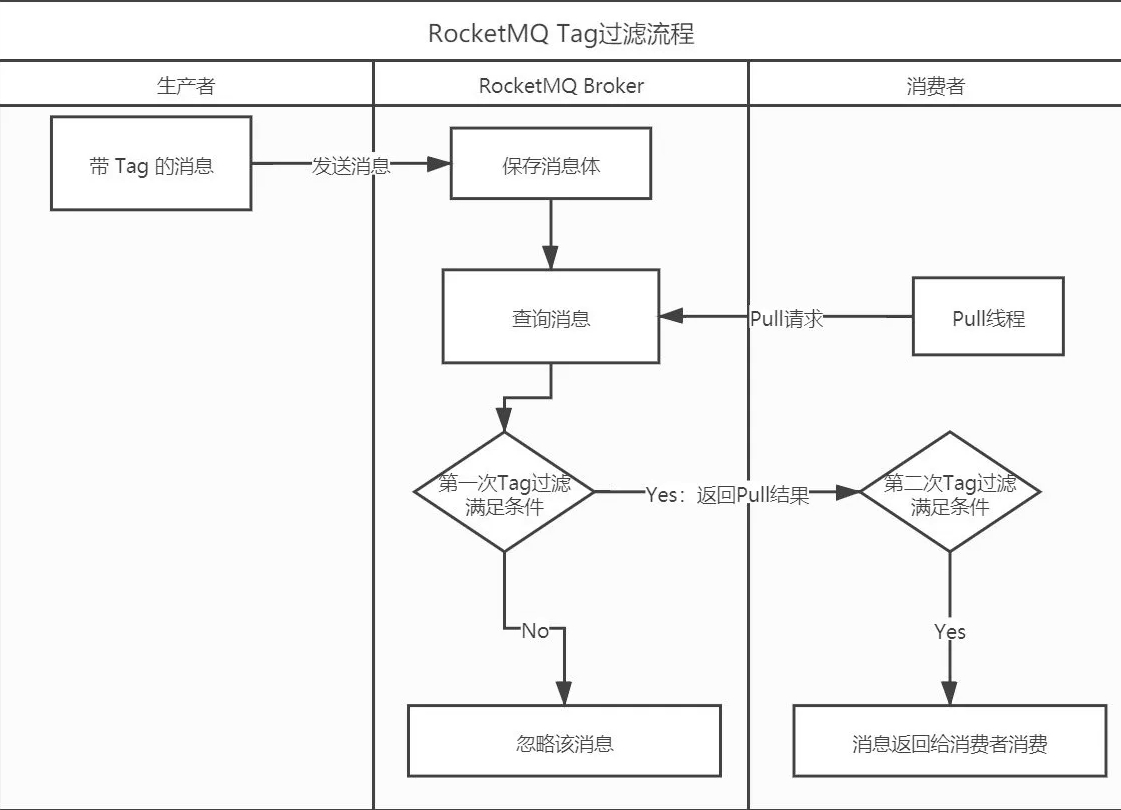
RocketMQ根据Tag消费数据
🔗🔗 【转载】 - java springboot rocketmq 如何根据tag消费数据 rocketmq消费多个tag
一、表达式过滤
其中表达式模式分为 TAG和SQL92表达式两种。
1. TAG(TAG 模式就是简单地为消息定义标签,根据消息的标签进行匹配。)
使用
在消息发送时,我们可以为每一条消息设置一个
TAG标签,消息消费者订阅自己感兴趣的TAG, 一般使用的场景是,对于同一类的功能(如:数据同步)创建一个主题, 但对于该主题下的数据,可能不同的系统关心的数据不一样,基础数据各个系统都需要同步,设置标签为ALL,而订单数据只有订单下游子系统关心,其他系统并不关心, 则设置标签为ORDER,库存子系统则关注库存相关的数据,设置标签为CAPCITY。消费者组订阅相同的主题不同的TAG,多个
TAG用“|”分隔,注意 :同一个消费组订阅的主题,TAG必须相同。
Producer代码示例:
@Slf4j
public class TestTagFilterProducer {
public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer("JING_GO_Producer", false);
producer.setNamesrvAddr("localhost:9876");
producer.start();
long l = System.currentTimeMillis();
try {
Message msg = new Message("test_topic",
"ORDER",
"OrderID188",
"Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg);
System.out.printf("cost:%s-->%s%n", (System.currentTimeMillis() - l), sendResult);
} catch (Exception e) {
log.error("", e);
}
producer.shutdown();
}
}
Consumer代码示例:
public class TestTagFilterConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("test-filter");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.subscribe("test_topic", "ORDER");
consumer.setNamesrvAddr("172.20.10.42:9976;172.20.10.43:9976");
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
💡💡 原理
消息发送者在消息发送时如果设置了消息的tags属性,存储在消息属性中,先存储在CommitLog文件中,然后转发到消息消费队列ConsumeQueue,消息消费队列 会用8个字节存储消息tag的 hashcode,之所以不直接存储tag字符串,是因为将ConumeQueue设计为定长结构,加快消息消费的加载性能。在Broker 端拉取消息时,遍历ConsumeQueue,只对比消息tag的hashoode,如果匹配则返回,否则忽略该消息。Consumer在收到消息后,同样需要先对消息进行过滤, 只是此时比较的是消息tag的值而不再是hashcode。
ConsumeQueue 存储格式如下

为什么过滤要这样做?
- Message Tag存储Hashcode,是为了在ConsumeQueue定长方式存储,节约空间;
- 过滤过程中不会访问CommitLog数据,可以保证堆积情况下也能高效过滤;
- 即使存在Hash冲突,也可以在Consumer端进行修正,保证万无一失;
- 优点是简单高效,缺点就是在Hash冲突时,并不是消费者订阅的消息,还会向消费者发送 。
流程图
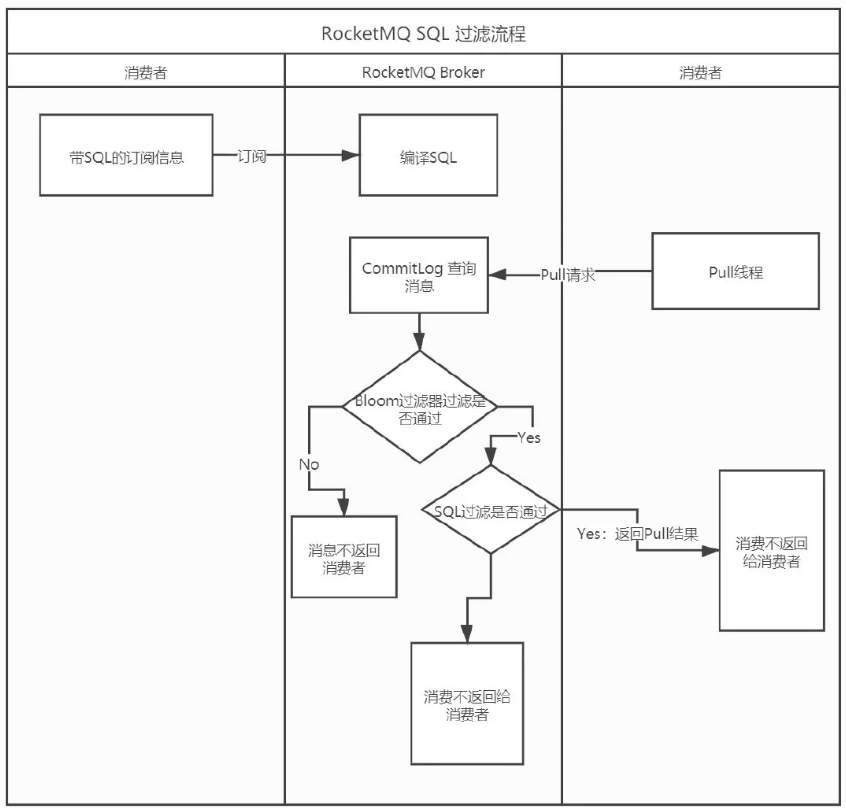
2. SQL92
TAG模式一个消息只能有一个标签,这对于复杂的场景可能不起作用。在这种情况下,可以使用SQL表达式筛选消息。SQL特性可以通过发送消息时的属性来进行计算,从而过滤出客户端订阅的消息。
使用
只有使用push模式的消费者才能用使用SQL92标准的sql语句;
使用Filter功能,需要在启动配置文件当中配置以下选项:enablePropertyFilter=true,否则会报错。
基本语法:
RocketMQ 仅仅提供了一些基本的语法来支持此特性:
1. 数值比较: >, >=, <, <=, BETWEEN, =;
2. 字符比较: =, <>, IN;
3. IS NULL or IS NOT NULL;
4. 逻辑: AND, OR, NOT;
常量类型如下:
1. 数字, 如: 123, 3.1415;
2. 字符, 如: ‘abc’, 必须是单引号;
3. NULL, 特殊常量;
4. 布尔, TRUE or FALSE;
Producer示例:
@Slf4j
public class TestSQL92FilterProducer {
public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer("zhurunhua", false);
producer.setNamesrvAddr("172.20.10.42:9976;172.20.10.43:9976");
producer.start();
long l = System.currentTimeMillis();
try {
for (int i = 1; i <= 10; i++) {
Message msg = new Message("test_topic",
"Apple",
"iPhone",
"测试过滤消息:SQL92".getBytes(StandardCharsets.UTF_8));
//设置属性(模拟10台不同序列号的苹果12手机)
msg.putUserProperty("name", "IPhone");
msg.putUserProperty("serial", "12");
msg.putUserProperty("color", "blue");
msg.putUserProperty("sequence", String.valueOf(i));
SendResult sendResult = producer.send(msg);
System.out.printf("cost:%s-->%s%n", (System.currentTimeMillis() - l), sendResult);
}
} catch (Exception e) {
log.error("", e);
}
producer.shutdown();
}
}
Consumer示例:
public class TestSQL92FilterConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("test-filter");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.setNamesrvAddr("172.20.10.42:9976;172.20.10.43:9976");
//过滤蓝色 序列号大于5的
String sql = "color = 'blue' and sequence > 5";
consumer.subscribe("test_topic", MessageSelector.bySql(sql));
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
💡💡 原理
功能设计图:
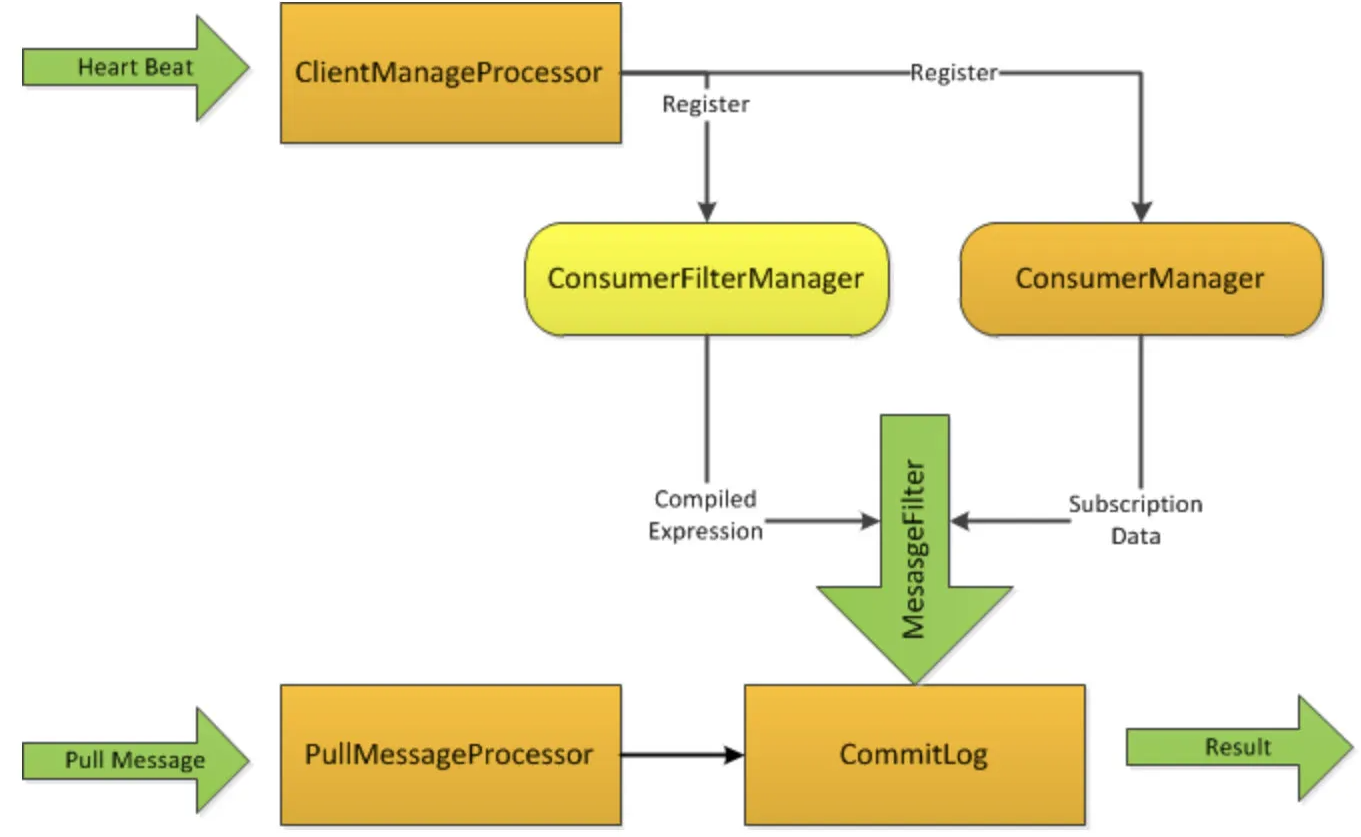
Broker通过心跳请求收集Consumer的SQL表达式,并保存在ConsumerFilterManager中;当使用者拉取消息时,
Broker将构造一个带有已编译好的表达式和订阅数据的MessageFilter(接口),用以在CommitLog中选择匹配的消息;
但是这样拉取消息时做过滤性能差,所以采用BloomFilter和预计算的方法进行优化:
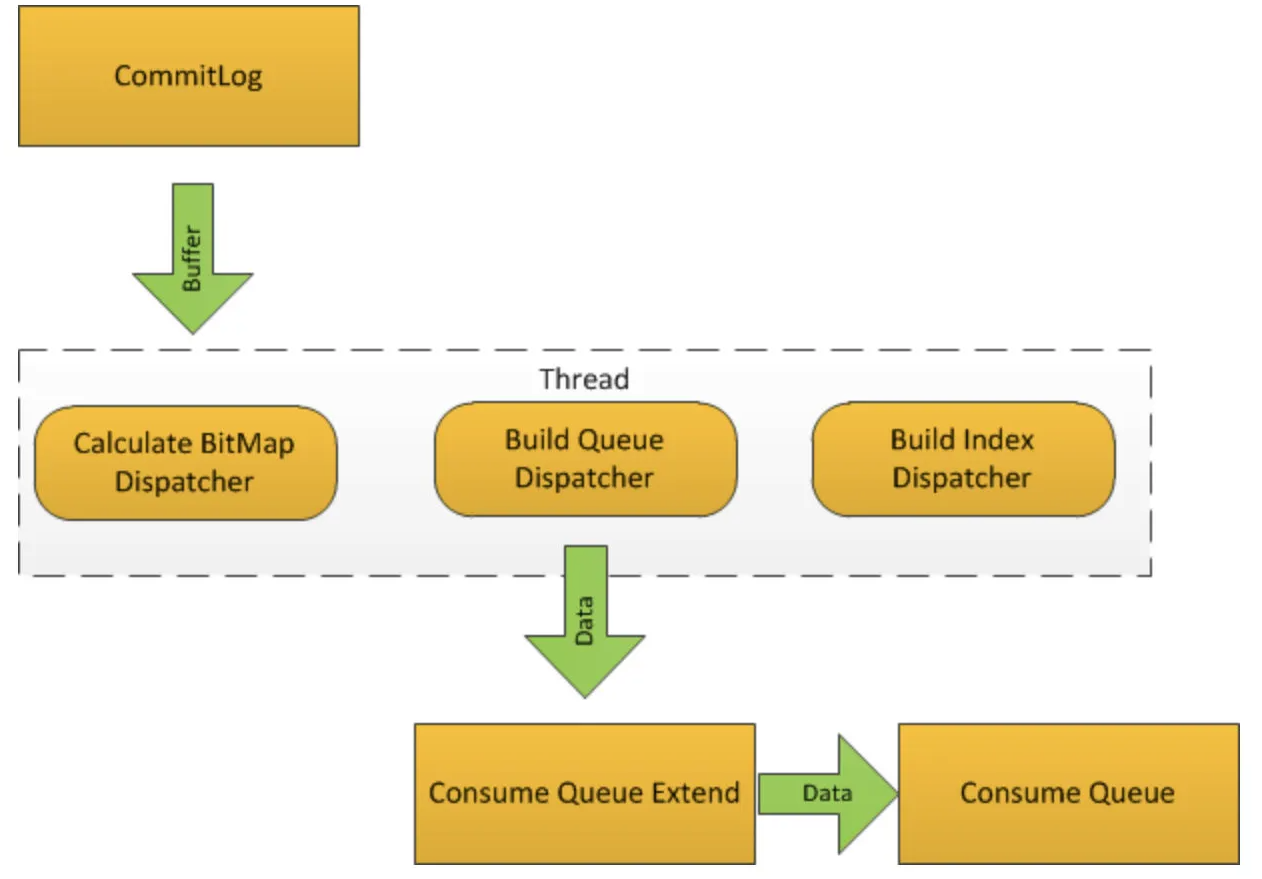
在
Broker理注册时,每个Consumer都被分配了BloomFilter的某个bit上;当消息写入
CommitLog后,Broker会构建ConsumeQueue,此时会计算消费者对应的过滤结果,所有的结果会保存到ConsumeQueueExt的bit数组中;ConsumeQueueExt是链接到ConsumeQueue的存储文件,
ConsumeQueue会根据tagsCode找到数据,tagsCode存的是ConsumeQueueExt生成的地址信息;ExpressionMessageFilter使用bit数组检查消息是否匹配。由于BloomFilter的冲突,它还需要解码消息属性来计算匹配的消息;
消费流程图: