- Published on
Centos7中部署Paddle2.3
一,下面是以 Anaconda 在Centos7.x 部署 Paddle 2.3
Anaconda环境配置
说明:使用
paddlepaddle需要先安装python环境,这里我们选择python集成环境Anaconda工具包Anaconda是一个常用的python包管理程序- 安装完
Anaconda后,可以安装python环境,以及numpy等所需的工具包环境
下载Anaconda:
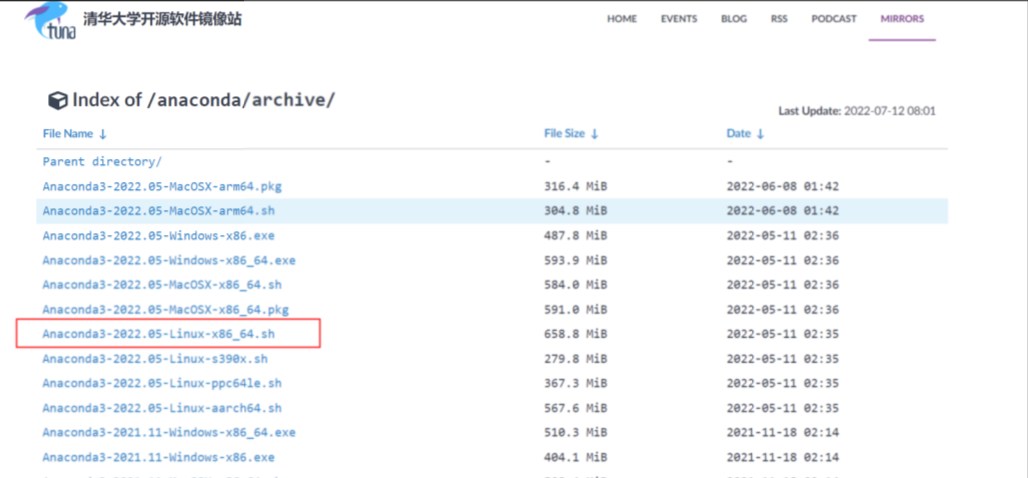
- 选择适合您操作系统的版本
- 可在终端输入
uname -m查询系统所用的指令集
我这里直接是在Linux 系统上面使用 wget 方式获取:
然后使用wget从清华源上下载# 如要下载
Anaconda3-2021.05-Linux-x86_64.sh,则下载命令如下:wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2022.05-Linux-x86_64.sh
若您要下载其他版本,需要将最后一个/后的文件名改成您希望下载的版本
安装
Anaconda:- 在命令行输入
sh Anaconda3-2021.05-Linux-x86_64.sh- 若您下载的是其它版本,则将该命令的文件名替换为您下载的文件名
- 按照安装提示安装即可
- 查看许可时可输入q来退出
- 在命令行输入
将conda加入环境变量
- 加入环境变量是为了让系统能识别
conda命令,若您在安装时已将conda加入环境变量path,则可跳过本步 - 在终端中的操作:
- 加入环境变量是为了让系统能识别
#打开 ~/.bashrc: 在终端中输入以下命令:
vim ~/.bashrc
#先按i进入编辑模式 默认安装路径 在第一行输入:
export PATH="/root/anaconda3/bin:$PATH"
# 若安装时自定义了安装位置,则将/root/anaconda3/bin改为自定义的安装目录下的bin文件夹
# 修改后的~/.bash_profile文件应如下(其中xxx为用户名):
export PATH="/root/anaconda3/bin:$PATH"# >>> conda initialize >>># !!
Contents within this block are managed by 'conda init' !!
__conda_setup="$('/root/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)
if [ $? -eq 0 ]; theneval "$__conda_setup"elseif [ -f "/root/anaconda3/etc/profile.d/conda.sh" ]; then
. "/root/anaconda3/etc/profile.d/conda.sh"else
export PATH="/root/opt/anaconda3/bin:$PATH"fifiunset __conda_setup# <<< conda initialize <<<
修改完成后,先按esc键退出编辑模式,再输入wq!并回车,以保存退出
- 验证是否能识别conda命令:
- 在终端中输入
source ~/.bash_profile以更新环境变量 - 再在终端输入
conda info —envs,若能显示当前有base环境,则conda已�加入环境变量
- 在终端中输入
- 创建新的
conda环境# 在命令行输入以下命令,创建名为paddle_env的环境# 此处为加速下载,使用清华源
conda create --name paddle_env python=3.7 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- 该命令会创建1个名为paddle_env、python版本为3.7的可执行环境,根据网络状态,需要花费一段时间
- 之后命令行中会输出提示信息,输入y并回车继续安装
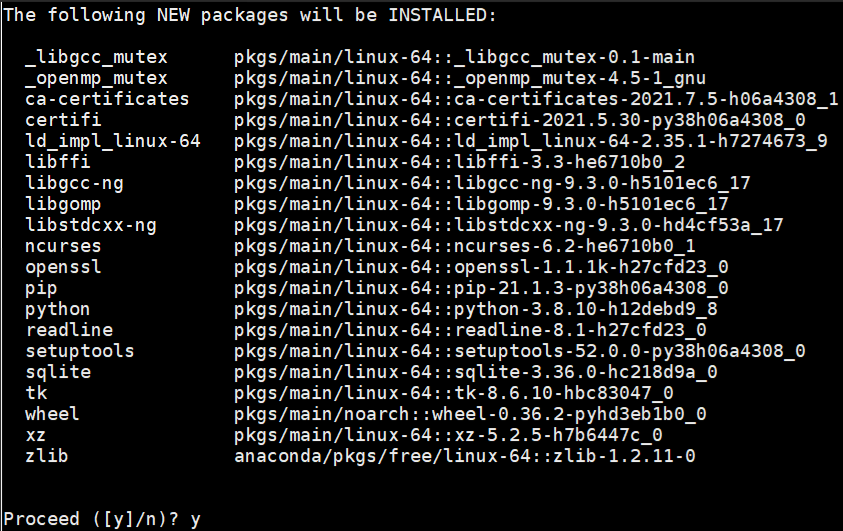
- 激活刚创建的conda环境,在命令行中输入以下命令:激活
paddle_env环境conda activate paddle_env以上anaconda环境和python环境安装完毕
二,下面是使用docker 的方式部署 Paddle 2.3 :(推荐)
# 切换到工作目录下cd /home/Projects
# 首次运行需创建一个docker容器,再次运行时不需要运行当前命令
# 创建一个名字为ppocr的docker容器,并将当前目录映射到容器的/paddle目录下
# 如果您希望在CPU环境下使用docker,使用docker而不是nvidia-docker创建docker
sudo docker run --name ppocr2 -v $PWD:/paddle --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.3.0-gpu-cuda10.2-cudnn7 /bin/bash
# 如果使用CUDA10,请运行以下命令创建容器,设置docker容器共享内存shm-size为64G,建议设置32G以上
# 如果是CUDA11+CUDNN8,推荐使用镜像
registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda11.2-cudnn8
sudo nvidia-docker run --name ppocr2 -v $PWD:/paddle --shm-size=64G --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.3.0-gpu-cuda10.2-cudnn7 /bin/bash
# ctrl+P+Q可退出docker 容器,重新进入docker 容器使用如下命令
sudo docker container exec -it ppocr /bin/bash
💥💥 注意:下面这些步骤不管是conda还是Docker 都是需要执行的:
安装 pip
注意:这里需要 docker container exec -it ppocr /bin/bash# 进入到容器里面执行python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
安装PaddleOCR whl包
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
项目克隆 (我这里使用的是 PaddleOCR-release-2.3)
git clone https://github.com/PaddlePaddle/PaddleOCR# 如果因为网络问题无法pull成功, 也可选择使用码云上的托管:git clone https://gitee.com/paddlepaddle/PaddleOCR
安装第三方库 mv PaddleOCR-release-2.3 PaddleOCRcd PaddleOCRpip3 install -r requirements.txt 安装paddlehub
paddlehub 需要 python>3.6.2
yum install mesa-libGL.x86_64pip3 install paddlehub==2.1.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple 下载推理模型: 安装服务模块前,需要准备推理模型并放到正确路径。默认使用的是PP-OCRv2模型,默认模型路径为: 下方文件已经打包压缩到:https://192.168.101.100:8443/svn/Java代码库/RedseaMicroservice/redseaocr 根目录检测模型:./inference/ch_PP-OCRv2_det_infer/识别模型:./inference/ch_PP-OCRv2_rec_infer/方向分类器:./inference/ch_ppocr_mobile_v2.0_cls_infer/
我的路径一般是PaddleOCR 项目文件主路径:
安装服务模块: 安装服务模块前,需要准备推理模型并放到正确路径。默认使用的是PP-OCRv2模型,默认模型路径为:
安装检测服务模块: hub install deploy/hubserving/ocr_det/# 或,安装分类服务模块: hub install deploy/hubserving/ocr_cls/# 或,安装识别服务模块: hub install deploy/hubserving/ocr_rec/# 或,安装检测+识别串联服务模块: 一般使用这个hub install deploy/hubserving/ocr_system/
4. 启动服务
方式1. 命令行命令启动(仅支持CPU)
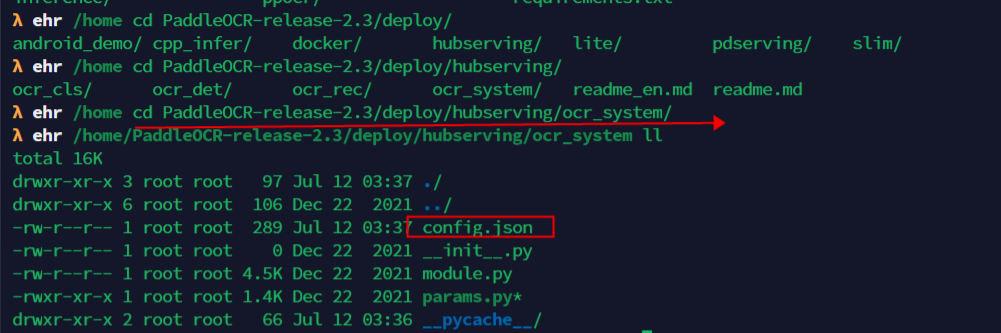
启动命令: hub serving start -c config.json 其中,config.json格式如下:
{
"modules_info": {
"ocr_system": {
"init_args": {
"version": "1.0.0",
"use_gpu": true
},
"predict_args": {}
}
},
"port": 8868,
"use_multiprocess": false,
"workers": 2
}
- init_args中的可配参数与module.py中的_initialize函数接口一致。其中,当use_gpu为true时,表示使用GPU启动服务(这里注意:use_gpu 要改成false)。
- predict_args中的可配参数与module.py中的predict函数接口一致。
发送预测请求
配置好服务端,可使用以下命令发送预测请求,获取预测结果: python tools/test_hubserving.py server_url image_path 需要给脚本传递2个参数:
- server_url:服务地址,格式为
http://[ip_address]:[port]/predict/[module_name]
例如,如果使用配置文件启动分类,检测、识别,检测+分类+识别3阶段服务,那么发送请求的url将分别是: http://127.0.0.1:8865/predict/ocr_det http://127.0.0.1:8866/predict/ocr_cls http://127.0.0.1:8867/predict/ocr_rec http://127.0.0.1:8868/predict/ocr_system
- image_path:测试图像路径,可以是单张图片路径,也可以是图像集合目录路径
- Web api 的接口方式通过 restTemplate的方式进行请求访问。返回结果为列表(list),列表中的每一项为字典(dict),信息如下:
返回结果格式说明
| 字段名称 | 数据类型 | 意义 |
|---|---|---|
| text | str | 文本内容 |
| confidence | float | 文本识别置信度或文本角度分类置信度 |
三,PaddleOCR 业务场景训练和使用
3.1 PaddleHub体验与应用
PaddleHub就是为了解决对深度学习模型的需求而开发的工具。基于飞桨领先的核心框架,精选效果优秀的算法,提供了百亿级大数据训练的预训练模型,方便用户不用花费大量精力从头开始训练一个模型。 参考链接: PaddleHub的课程地址:https://aistudio.baidu.com/aistudio/course/introduce/1070 PaddleHub的教程地址:https://aistudio.baidu.com/aistudio/personalcenter/thirdview/79927 PaddleHub的模型地址:https://github.eom/PaddlePaddle/PaddleHub/tree/release/vl.6/demo
3.2 EasyDL体验与应用
EasyDL零门槛AI开发平台 快速搭建模型训练和简单上手,但是是需要web api 和收费,下图是企业用户收费:
